And Serve You French Toast (Data) Again 1: Collect and Clean
08 Apr 2022
French toast is one of the few things I think I’ve cooked more than half a dozen times. That’s probably what compelled me to attempt a data analysis project of french toast recipes. After all, with the internet, untold french toast recipes lay at my finger tips. Just what secrets could we unlock looking into their depths? Probably not much, but at least I’d get a gee-whiz data analysis 101 project out of it.
 French toast is great.
French toast is great.
No really, why I am doing this exactly??
Usually, data anlaysis is done to answer a question, test a hypothesis, etc. But I didn’t really have any clear cut reasons from the beginning. That’s part of the fun of doing personal project; when I’m interested in something, I like to just jump in and get started.
That being said, I still had *some* ideas, such as:
- If you had enough recipes, could you normalize the data and figure out an “average” version of that recipe?
- How many types of bread, eggs, and milk/cream (i.e. essential ingredients) would you find among french toast recipes?
- What kind of variations of french toast are there?
- What are the unique ingredients beyond the bread, eggs, and milk/cream?
I am simply here to collect data
I found some recipe data more or less put together on GitHub, user onzie9’s all_recipe_data . 250k+ recipe ingredients scraped from allrecipes.com and organized into text files. Below is an example of the content of those text files. Each recipe has a “=” delimiter, recipe title, recipe number and type, and ingredient list.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
=======================================
mexican-strawberry-water-agua-de-fresa
3 main
[4 cups strawberries, sliced
1 cup white sugar
8 cups cold water
1 lime, cut into 8 wedges (optional)
8 fresh mint sprigs (optional)]
=======================================
crispy-cheese-twists
6663 main
[1/2 cup Parmesan cheese
3/4 teaspoon ground black pepper
1/2 teaspoon garlic powder
1 (17.5 ounce) package frozen puff pastry, thawed
1 egg white]
=======================================
basil-roasted-peppers-and-monterey-jack-cornbread
6664 Bread
...
[recipes continue]
How the tables turn
This was pretty good. But I wanted this “raw data” to be restructured into a tabular format instead, something I could manipulate as a Pandas data frame and save as a CSV file.
I used Python to get there, starting with defining the GitHub data locations on my computer.
1
2
3
4
5
6
import regex as re
import pandas as pd
raw_recipe_data_dir = "all_recipes_data-master/DataFiles/"
raw_data_list = ["raw_data_1.txt", "raw_data_2.txt", "raw_data_3.txt",
"raw_data_4.txt"]
Then I define a regex pattern for extracting the data.
1
2
pattern = r"=======================================(?:\n|\r\n?)((?:.+))(?:\n|\r\n?)((?:.+))(?:\n|\r\n?)(\[(?:[^=]|\n)+\])"
recipereg = re.compile(pattern)
See the screenshot from regex101.com below for an overview of how this works out. The recipe title, number and type, and ingredients correspond to the capture groups i.e. the regex in parentheses “(…)”. The non-capture groups, i.e. the regex in “(?:…)”, are ignored.
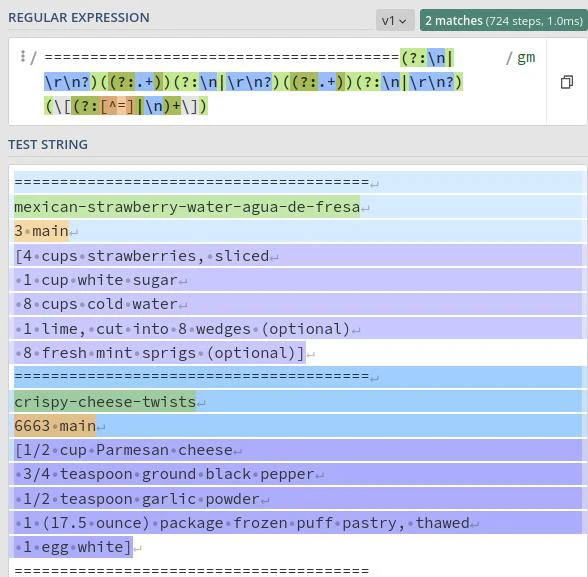 Regex pattern for recipe data in text files.
Regex pattern for recipe data in text files.
The next part of code iterates through each text file, applies the regex pattern, and saves matches into a Pandas data frame.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
df = pd.DataFrame(columns=["Title", "Type", "Ingredients"])
for fn in raw_data_list:
# get text file contents
f_loc = raw_recipe_data_dir + fn
f = open(raw_recipe_data_dir + fn)
contents = f.read()
# find regex pattern matches in contents
m = re.findall(pattern, contents)
# input matches into dataframe
df_temp = pd.DataFrame(columns=["Title", "Type", "Ingredients"])
df_temp["Title"] = [x[0] for x in m]
df_temp["Type"] = [x[1] for x in m]
df_temp["Ingredients"] = [x[2] for x in m]
df = df.append(df_temp)
Boom, that’s our data in tabular form.
The First Cut Is The Deepest
Next, I wanted to get the approximate subset of recipes for french toast. I used a simple solution: just drop the recipe if its title did not contain both “french” and “toast”.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# drop unnecessary columns
df = df.drop('Type', axis=1)
# make sure everything is lowercase
df["Title"] = df["Title"].str.lower()
df["Ingredients"] = df["Ingredients"].str.lower()
# drops rows that don't contain "french" and "toast" in the title of recipe
df = df[(df["Title"].str.contains("french")) & (df["Title"].str.contains("toast"))]
# drop duplicate rows
df = df.drop_duplicates()
# double check ingredient frequency / no duplicates
count_ingredients = df["Ingredients"].value_counts()
# write CSV
df["Ingredients"] = df["Ingredients"].str.strip('[]')
df.to_csv("french_toast_recipes.csv", index=False)
This also simplifies things by ignoring other names for french toast, of which there are quite a few , such as the French “pain perdu” or the British “eggy bread”.
And there we go, I now had what presumably could be considered an alright set of french toast recipes from this allrecipes.com data set.
 Example of what the tabular data looks like.
Example of what the tabular data looks like.
You’re Gonna Clean That Data
 French toast casserole? Doesn’t count.
French toast casserole? Doesn’t count.
So that was pretty easy and cool, but I was far from being done. Just because “french” and “toast” were in the title, doesn’t mean these were real deal french toast recipes. Furthermore, it didn’t take long to figure out the ingredients data was, from an analysis perspective, junk. The units and quantities were not separated, even the simplest ingredients had dozens of variants, some lines had multiple ingredients in them, etc. A cleanse was in order.
At the start, I hadn’t realized the hard task I had haphazardly jumped into. My cleaning process at the start was pretty “whatever”, I learned as I went, and it was iterative. I would clean data in one dimension, stepped back to clean in another, then re-do a previous cleanse, etc. I ended up writing 7 Python script files that either cleaned the data or helped me inspect / visualize it. Interwoven into the cleaning process was additional restructuring as well.
Here’s a summary of the cleaning process:
- Do “quality checks” on the data. For example, below I am checking the unique values in the “flavor” category. It’s a quick read on unique values and how often they appear, and therefore makes it easy to spot anomalies such as duplicates, typos, missing values, etc.
1
qc_check_flavor = ft_recipes.loc[ft_recipes["category"] == "flavor", ["ingr"]].value_counts()
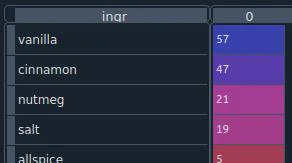 Example of flavor value counts. Shout out to Spyder’s variable explorer.
Example of flavor value counts. Shout out to Spyder’s variable explorer.
- Cut out recipes that did not meet certain french toast qualifications. For example, the code below cuts out recipes that do not have the core ingredients of bread, eggs, and milk/cream.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# looking for recipes that don't have basic ingredients (bread, milk, eggs)
# bread
bread = ["bread", "toast", "baguette", "croissant", "hawaiian",
"challah", "brioche", "mexican bolillo rolls", "pannetone",
"italian bread"]
mask_bread = ft["Ingredients"].str.contains(r'\b(?:{})\b'.format('|'.join(bread)))
ft[~mask_bread].to_csv("0_cut_ft_recipes/french_toast_recipes_cut_no_bread.csv",index=False)
#milk
milk = ["milk", "milks", "half-and-half", "half and half", "heavy whipping cream",
"heavy cream", "egg nog", "eggnog", "whipping cream", "light cream",
"mascarpone cheese", "irish cream liqueur"]
mask_milk = ft["Ingredients"].str.contains(r'\b(?:{})\b'.format('|'.join(milk)))
ft[~mask_milk].to_csv("0_cut_ft_recipes/french_toast_recipes_cut_no_milk.csv",index=False)
# eggs
eggs = ["egg", "eggs", "egg substitute", "egg beaters"]
mask_egg = ft["Ingredients"].str.contains(r'\b(?:{})\b'.format('|'.join(eggs)))
ft[~mask_egg].to_csv("0_cut_ft_recipes/french_toast_recipes_cut_no_egg.csv",index=False)
mask = mask_var & mask_bread & mask_milk & mask_egg
ft_non = ft[~mask]
ft_clean = ft[mask]
- Another example: cutting out french toast variations. Some of these were straight abominations and would never pass as french toast, e.g. “casseroles” and “souffles”. Others were straddling the line of french toast purity. Ultimately, I chose the more “purist” approach (see further below for the whole “does baked count” thing).
1
2
3
4
5
6
7
8
9
import pandas as pd
ft = pd.read_csv("french_toast_recipes.csv", index_col=False)
# removing variants
var = ["casserole", "sandwhich", "sandwich", "sandwhiches", "sandwiches", "stick", "sticks",
"fingers", "bites", "roll-ups", "banana-roll", "cookies", "wrapped-in-bacon",
"toast-bake", "kabobs", "strata", "souffle", "soufle", "cobbler", "in-a-cup",
"baked", "bake", "cups", "slow-cooker", "no-fry", "overnight"]
mask_var = ~(ft["Title"].str.contains(r'\b(?:{})\b'.format('|'.join(var))))
ft[~mask_var].to_csv("0_cut_ft_recipes/french_toast_recipes_cut_variants.csv",index=False)
- Break down data into ingredient (just words), units, and quantities. Easy enough to separate numbers from words. We can even apply a first guess of the units by looking at first word that occurs after the first number. But after that, it required a lot of manual data review to get correct breakdowns.
- Simplify and categorize the ingredients. I wanted to make the data more uniform and simplify many variants of what were (basically) the same ingredients. For example, see below. The category is easy enough, this is the milk/cream used for the custard. However, notice that “1% fat milk” was changed to “low fat milk”. I did this because, as a culinary cipher like myself finds out, there are quite a few variations of milk and names for defining them. “1% milk” is the same as “low fat milk”, but other recipes would use one or the other, so I had to choose just one name for all recipes. Another example: some ingredients had “or”s in them, e.g. “italian or french bread”, and for those I decided to always go with the first option.
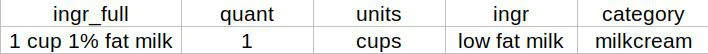
Example of ingredient breakdown.
Bake? Or nah?
The largest issue / side quest I ran into was deciding whether “baked” variants of french toast were allowed. After I thought I was mostly done with cleaning, I did some research, and decided french toast had to be fried/sautéed. Therefore, I decided to cut all recipes that were primarily cooked through baking. Unfortunately, this ended up being quite involved. After trying to make cuts off of titles and ingredients alone, I realize I would have to look at the recipe instructions to determine if the recipe was baked or not.
Problem was, the instructions were not included in the data I had. But I had to commit to what I started, so I ended up writing an entire new Python script just to scrape data from allrecipes.com and acquire the missing instructions. Then it was a long process of manually checking each of the suspect recieps to determine how they were cooked. Despite the challenge, this worked out nicely and I think I succeeded in my purge. But it also cut out many recipes, to the point where I wondered if I was being too much of a purist.
It’s Over
At the end of the process, each ingredient had been broken down into components: a quantity, units, cut, name of ingredient, category and subcategory. Special attention was paid to bread, milk/creams, and eggs.
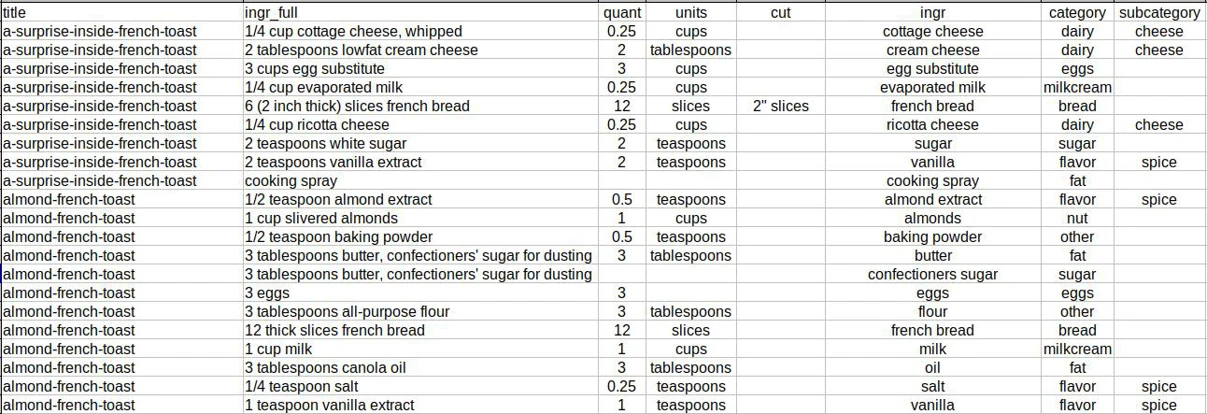 Sample of final cleaned data set.
Sample of final cleaned data set.